검색엔진이 왜 필요한가?
RDBMS의 where 절로 검색이 가능한데 왜 ElasticSearch와 같은 검색엔진이 필요한가하면,
- RDBMS는 단순 텍스트 매칭 검색기능만 제공.
- 텍스트를 여러 단어로 변경하거나 텍스트의 특징을 이용한 동의어 유의어 활요한 검색가능. (= 고급검색가능)
- 비정형 데이터의 색인과 검색 가능.(매우 중요한 부분. 사용이유.)
- 자연어 처리 가능.
- 역색인 지원으로 매우 빠른 검색 가능.
특징
- 실시간 처리 불가능.
- 트랜잭션, 롤백기능 제공안됨. 데이터 관리가 불안정.
- 업데이트 기능이 없음. 업데이트 기능이 있긴하나 삭제하고 다시등록하는 과정.
- 내부적으로 역색인이 됨
- 전문검색이 가능.
데이터 구조
text 단어를 기준으로 document를 저장하는 방식
| text | document |
| 안녕하세요 | doc1,doc2,doc3 |
| 개발 | doc2,doc5 |
ElasticSearch와 RDB 비교
| ElasticSearch | RDB |
| Index | Database |
| Type | Table |
| Document | Row |
| Field | Column |
| Mapping | Schema |
ElasticSearch의 CRUD는 Rest API 를 따른다.
GET : 조회
POST : 생성
PUT : 변경
DELETE : 삭제
ElasticSearch 색인 과정
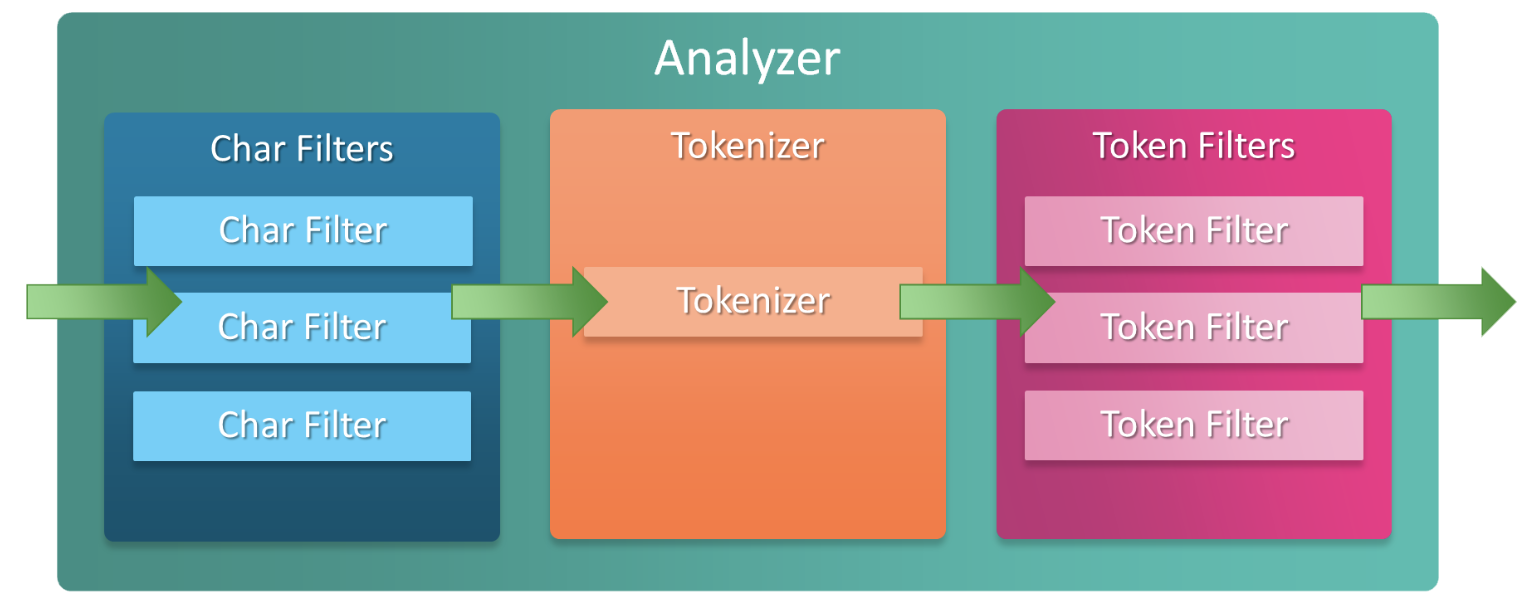
위 과정을 텍스트 분석(Text Analysis)이라고 함.
Char Filters
입력된 원본의 텍스트를 분석에 필요한 형태로 변환하는 역할
Tokenizer
입력 데이터를 설정된 기준에 따라 검색어 토큰으로 분리하는 역할
standard
-, []와 같은 기호는 구분자로 인식하고 분리한다.
whitespace
띄어쓰기, 탭, 줄바꿈과 같은 공백 기준으로 토큰 분리
nGram
최소-최대 길이에 해당하는 문자들을 토큰으로 분할한다.
중요한 필드를 두세 개의 문자만 가지고도 검색 가능하지만
검색어 토큰이 많아지기 때문에 메모리 사용량과 시스템 부하 역시 증가한다.
edgeNGram
nGram의 문제점을 해결하기 위해 등장한 edgeNGram
검색어의 모든 값을 분할하는 것이 아니라 문장의 시작 부분만 분할한다.
keyword
입력된 문장 전체를 하나의 싱글 토큰으로 저장
letter
알파벳이 아닌 공백/특수문자 기준으로 검색어 토큰 분리
아시아 쓰는 언어에서는 오동작 주의해야 한다.
lowercase
letter -> lowercase filter 적용한 것과 동일
Token Filter
분리된 토큰들에 다시 필터를 적용해서 실제로 검색에 쓰이는 검색어들로 최종 변환하는 역할
분석단계에서 가장 중요한 과정
porter_stem
Porter Stemming 알고리즘을 적용한 형태소 분석을 하는 토큰필터
lowercase 토크나이저를 미리 적용해야 한다.
shingle
문자열을 토큰-Ngram 방식으로 분석하는 기능
word_delimiter
입력된 문장의 단어를 더 세부적으로 분할하거나 병합하는 다양한 옵션들을 제공
snowball
원형으로 변환하는 토큰 Filter. days -> day
참고자료 :
https://nesoy.github.io/articles/2019-03/ElasticSearch-Analysis